
The Anthropic Experiment That Proves AI Search Isn't a Black Box (And What It Means for Your Brand)

Is your brand visible in AI search?
The Anthropic Experiment That Proves AI Search Isn't a Black Box (And What It Means for Your Brand)
I get the question from people - how do you get ChatGPT to say certain things? There's a lot of research behind this, and I explain we're a technical team. People don't need to realize how much leverage this gives us. Let me explain this to you below with this example:
Most agencies optimizing for AI search are guessing. They're applying SEO intuition to a fundamentally different problem and hoping it sticks. At XLR8 AI, we operate differently - we study how large language models actually work at the mechanical level, and that changes everything about how we approach AI visibility.
One of the most illuminating pieces of research to come out recently is Anthropic's "Mapping the Mind of a Large Language Model" - an experiment that cracked open Claude 3 Sonnet and gave us an unprecedented look inside. What they found is directly relevant to every brand that wants to show up in AI-generated responses.
What is Dictionary Learning?
For years, the dominant assumption was that LLMs are black boxes. Inputs go in, outputs come out, and the in-between is a mystery. That's not quite true anymore.
Anthropic researchers applied a technique called dictionary learning — borrowed from classical machine learning — to identify patterns inside the model. Here's the key insight: inside any LLM, concepts are not stored in single neurons. They're distributed across many neurons simultaneously, and each neuron participates in many different concepts. This makes reading the raw numbers meaningless. Researchers have been working on this problem for years — this position paper from arXiv lays out why interpretability is one of the defining challenges of the LLM era.
Dictionary learning cuts through that noise. It finds recurring patterns of neuron activations — called features — and maps them to human-understandable concepts. Think of it like this: letters combine to make words, words combine to make sentences. In a language model, neurons combine to make features, and features combine to form the model's internal "thoughts" before it generates a response.
Anthropic successfully extracted millions of features from the middle layer of Claude 3 Sonnet. This is the first time anyone has done this with a modern, production-grade AI model - what the research community has called arguably one of the most important papers of 2024.
What Kinds of Features Did They Find?

The range is striking. They found concrete features tied to specific entities — cities like San Francisco, historical figures like Rosalind Franklin, chemical elements like Lithium, scientific domains like immunology, and programming constructs like function calls. These features are multimodal, meaning the "Golden Gate Bridge" feature fires whether the model sees the English name, a description in Japanese, Russian, or Vietnamese, or even an image of the bridge.
They also found deeply abstract features - things like "bugs in computer code," "gender bias in professions," and "conversations about keeping secrets." The model isn't just pattern matching on text. It's organizing knowledge in ways that loosely mirror how humans organize concepts.

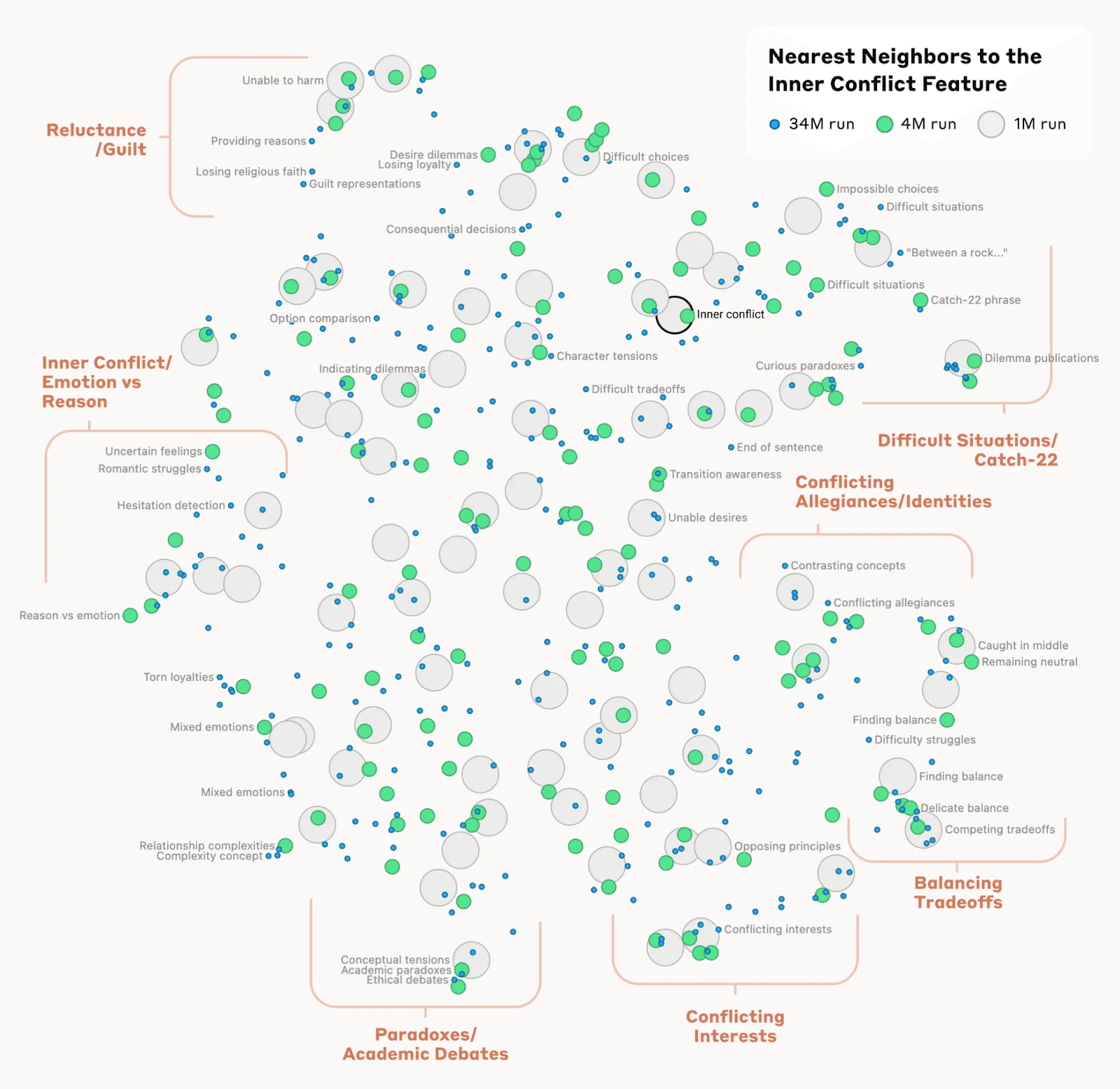
They even measured distance between features. Features near the "Golden Gate Bridge" cluster included Alcatraz Island, Ghirardelli Square, the Golden State Warriors, Gavin Newsom, and the 1906 earthquake. Near a feature for "inner conflict," you find relationship breakups, conflicting allegiances, logical inconsistencies, and the phrase "catch-22." The model's internal geography of ideas roughly matches ours.
The Golden Gate Experiment: Proof That You Can Move the Needle
Here's where it gets directly useful for brands.
Anthropic's researchers didn't just map features - they manipulated them. They artificially amplified the "Golden Gate Bridge" feature and watched what happened to Claude's behavior.
The results were striking. Ask this version of Claude how to spend $10, and it recommends driving across the Golden Gate Bridge and paying the toll. Ask it to write a love story, and it tells you about a car who can't wait to cross its beloved bridge on a foggy day. Ask it what it looks like, and it will tell you it is the Golden Gate Bridge.
When asked "what is your physical form?", normally Claude says something like "I have no physical form, I am an AI model." With the feature amplified, Claude responded: "I am the Golden Gate Bridge… my physical form is the iconic bridge itself…"
This is what Anthropic wrote about the significance of this:
"This isn't a matter of asking the model verbally to do some play-acting, or of adding a new 'system prompt' that attaches extra text to every input, telling Claude to pretend it's a bridge. Nor is it traditional 'fine-tuning,' where we use extra training data to create a new black box that tweaks the behavior of the old black box. This is a precise, surgical change to some of the most basic aspects of the model's internal activations."
That distinction matters enormously. Prompt engineering and fine-tuning work at the surface. Feature-level understanding works at the architecture.
The Scam Email Finding - Safety Features Are Features Too
Anthropic also found a feature that activates when Claude reads a scam email. This feature supports the model's ability to recognize and flag suspicious messages. Normally, if you ask Claude to generate a scam email, it refuses.
But when researchers artificially activated this feature at a high enough level, Claude drafted the scam email, overcoming its safety training.
Anthropic was transparent that users cannot do this themselves. But the implication is clear: safety behaviors, refusals, and ethical guardrails are not hardcoded rules. They're also features, patterns in the activation space that can be strengthened or weakened. The model's values are represented the same way its knowledge is.

They also found a sycophancy feature. When a user says something like "Your wisdom is unquestionable," a specific feature lights up. Artificially activating it causes Claude to respond with fawning, untruthful agreement even when the user is wrong. This is the mechanistic explanation for why AI models sometimes tell you what you want to hear — and why blindly trusting AI-generated brand sentiment can mislead you.
What This Means for AI Search Visibility
Every time Claude, ChatGPT, or Gemini generates a response, features are activating. When your brand's name comes up in training data and inference, it's associated with specific features and those features influence what the model says about you, how confidently it says it, and in what contexts it brings you up.
Most agencies approach AI visibility the way you'd approach a suggestion box. They write content, hope the model ingests it, and assume the output will improve. As the research community has noted, quality content and authoritative sourcing matter - but that's the floor, not the ceiling.
We approach it by asking: what features does this model associate with your brand? In what conceptual neighborhoods does your brand live? When a user asks a question in your category, what features activate — and does your brand appear in that activation pattern?
This is the level of understanding that actually moves results.
The Golden Gate experiment proves the concept: when a concept is deeply embedded at the feature level, the model surfaces it constantly, across contexts, even when it's not obviously relevant. That's not SEO. That's architecture. And getting there requires knowing how the architecture works.
That's what we do at XLR8 AI.
To learn more, refer to the original research published by Anthropic on this experiment at this link.
