Source details: URL vs. domain views, source-type buckets, and citation mix

We've added a Source Details view to every Experiment that turns the raw citation array into the analytics layer your content team has been asking for.
What's new
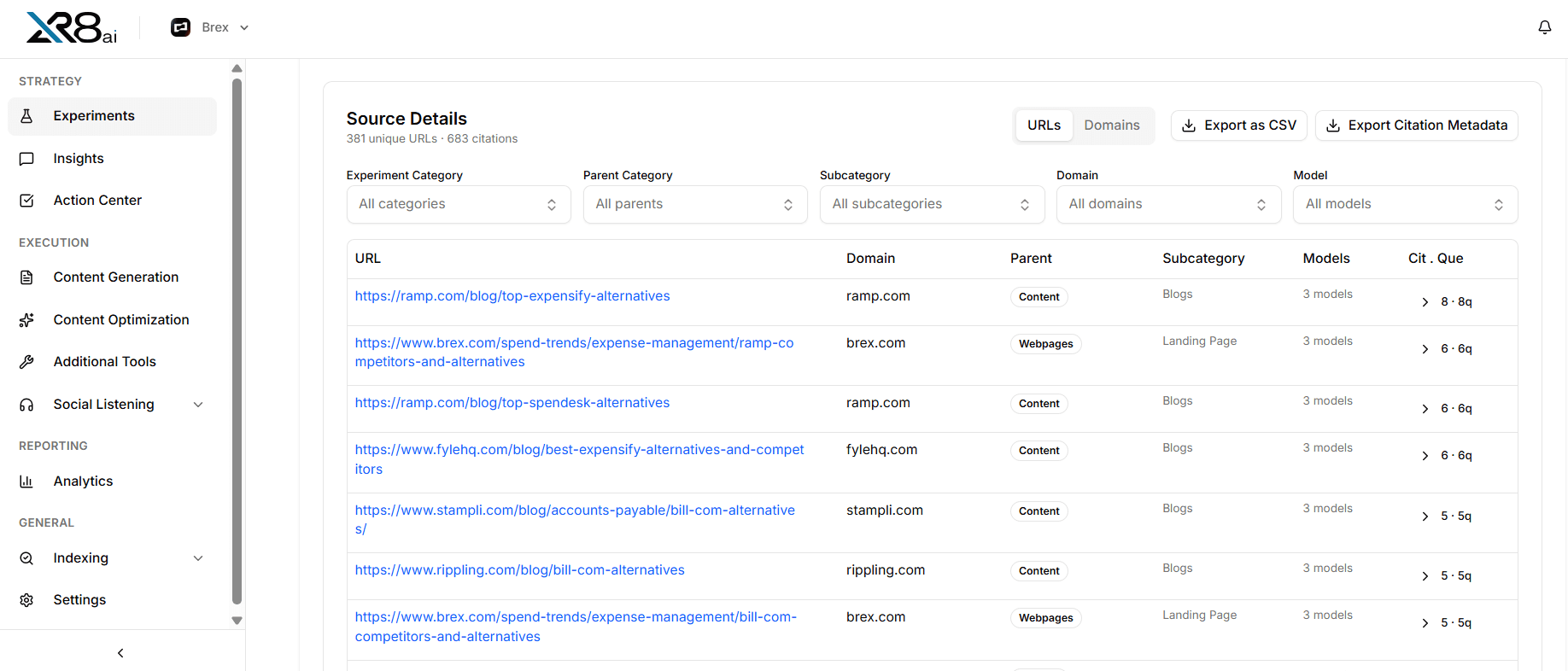
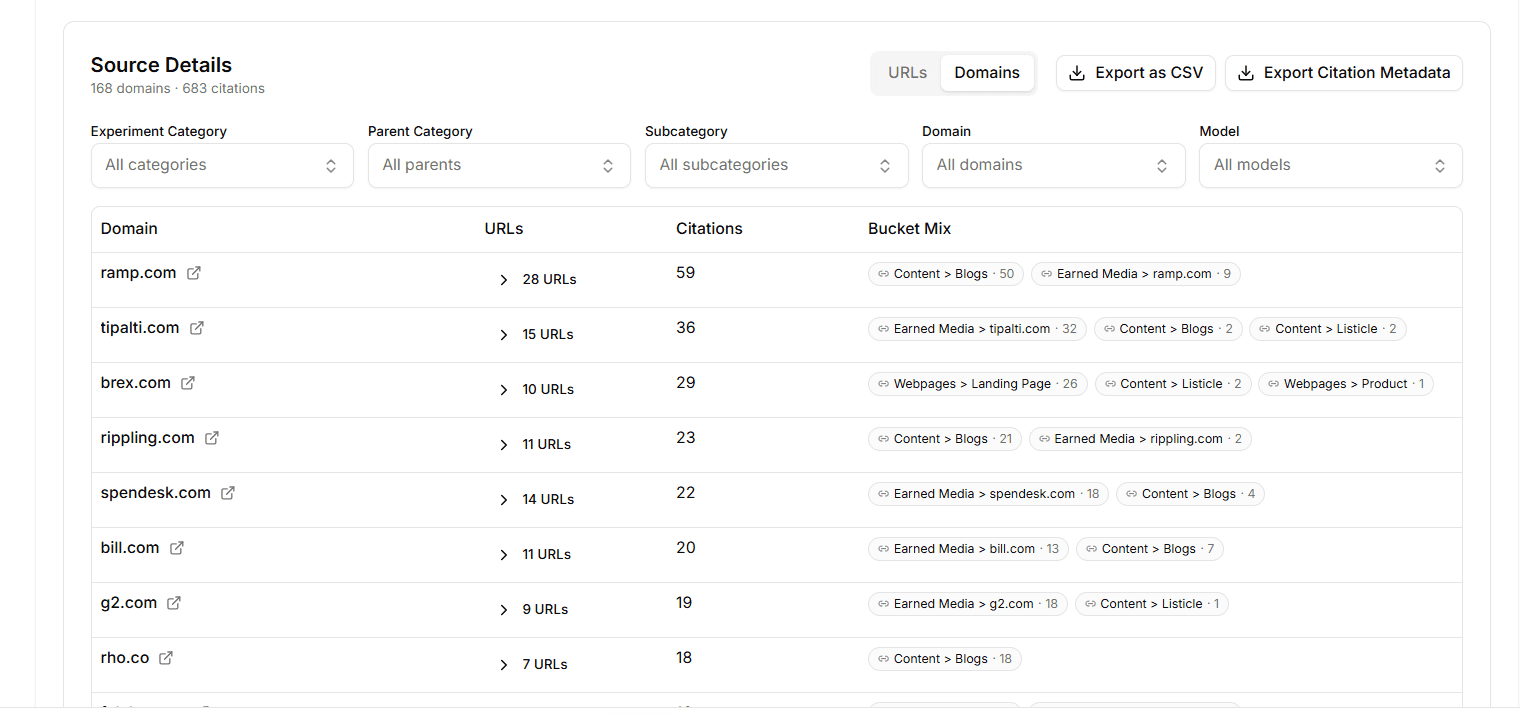
URL ↔ domain toggle. See the top cited URLs (the specific pages models actually link to) or roll them up to the domain level (so you can see who's winning the category, not just which post is winning a query).
Source-type buckets. Every cited URL is auto-classified into one of five buckets: your pages, competitor pages, review/comparison sites, third-party content, or social/forums. The split tells you whether LLMs are trusting your own site or sending buyers somewhere else.
Citation mix per category. A stacked-bar view showing the bucket mix per category in your Experiment. Categories where third-party sites dominate the mix are usually the most concrete opportunity for owned content.
Why it matters
The citation array on each Experiment result is rich, but it's been hard to see the patterns across hundreds of rows. Source Details puts a slice over it that answers the three questions every content team asks: who's getting cited, are they us or not, and where are we underrepresented.
Available today
Source Details is live in every Experiment under the Sources tab. The Insights Agent can also answer source-type questions directly — try "which categories have the highest third-party citation share?"
